
Member
| 이름 | 학과 | 학번 | 역할 | |
|---|---|---|---|---|
| 이홍준 | 기계공학부 | 2015011203 | lhj9606@hanyang.ac.kr | Everything |
0. Video Summary
https://www.youtube.com/watch?v=7J8GE4Yonug
1. Proposal (Option A)
4차 산업혁명 시대가 대두되면서, 여러 기술들이 발전하고 주목받고 있지만 그 중에서도 우리 생활에 밀접하게 관련있고, 접근성이 좋은 기술 중 가장 주목받는 기술 중 하나를 꼽자면 바로 ‘자율주행’ 기술일 것이다. 이러한 자율주행 기술이 급격하게 발전하게 된 이유 중 하나는 Deep Learning(Deep Neural Network)의 발전, 그리고 CNN(Convolutional Neural Network) 등의 등장으로 인한 컴퓨터 비전(CV, Computer Vision) 분야의 많은 기술적 도약이 있었기에 가능해졌다.
1.1. Need
자율주행 자동차는 ‘인지’, ‘판단’, ‘제어’의 3가지 Step으로 스스로 주행을 관장하는데, ‘인지’ 단계에서 카메라(Camera), 레이더(Rader), 라이다(LiDAR) 등의 여러 센서로 부터 취합한 정보를 바탕으로 차량 주변의 환경을 인식하며, 이를 토대로 ‘판단’과 ‘제어’를 수행한다. 즉 ‘인지’ 단계가 자율주행 알고리즘에 있어 가장 첫번째 단계이므로, 자율주행에서 가장 중요하면서도 차량의 주변 환경을 명확하게 인식해야만 안전한 주행이 가능하기 때문에 매우 중요한 단계라고 할 수 있다.
이러한 ‘인지’ 수행 과정에서 카메라, 레이더, 라이다 등의 센서 정보들 모두 중요하며, 각각의 장단점으로 인해 상호보완적으로 사용되지만, 물체의 종류를 식별하는 데에 가장 중요한 정보는 바로 ‘카메라 데이터’ 이다.
위의 [Tesla의 자율주행 예시 영상] 내의 우측의 카메라 영상 처리 결과를 보면 알 수 있다시피 카메라 데이터를 차량의 자율주행의 정보로 활용하는 모습을 볼 수 있다.
본 프로젝트에서는 ‘인지’ 단계에서의 자율주행 차량이 어떻게 주변 사물을 인식하는지 알아보기 위해 ‘카메라 데이터’를 입력으로 받고 이를 검출해내는 모델(YOLOv5 사용)을 만들어 볼 것이다.

1.2. Objective
본 프로젝트는 YOLOv5를 기반으로 하여, 자율주행 환경에 필요한 이미지들을 모델에 학습하고, 자율주행 환경에 필요한 이미지 검출 속도에 맞게 모델을 튜닝할 예정이다.
학습된 모델을 토대로 실제 차량에 탑재하여, 실제 차량과 그 이외의 주행 상황에 등장 가능한 물체에 대한 인식을 검출하는 시도를 하면 좋겠지만, 실제 차량에 컴퓨터와 카메라를 탑재하여 이를 검증해보는 것이 어렵다. 따라서, 본 프로젝트에서는 자율주행 환경을 모사 가능한 일부 게임 (ex. GTA5, Forza Horizon 등)의 화면 데이터를 카메라 데이터로 대응시켜 모델의 객체 검출이 잘 이뤄지는지 확인해볼 예정이다.
2. Datasets
자율주행을 위한 딥러닝 학습용 Open Dataset은 다양하게 공개가 되어있다.
2.1. KITTI Dataset
http://www.cvlibs.net/datasets/kitti/
KITTI Dataset은 현존하는 자율주행 Dataset 중에서 가장 많이 사용되는 Dataset으로 자율주행의 다양한 인지 Task를 위한 라벨링(Annotation)을 제공한다. 2D/3D 물체 검출(Object Detection)은 물론 물체 추적(Tracking), 거리 추정, Odometry, 스테레오 비전, 영역 분할 등의 Task에 활용될 수 있다. 또한 알고리즘 벤치마크를 위한 리더보드도 제공한다.


KITTI Dataset은 개조된 Volkswagen Passat B6을 이용하여 데이터를 수집하였으며, 데이터의 처리 및 저장은 Intel i7 CPU와 Linux OS를 이용하였다.
데이터 수집을 위해 개조된 차량의 센서 구성은 다음과 같다.
- 1 Inertial Navigation System (GPS/IMU): OXTS RT 3003
- 1 Laserscanner: Velodyne HDL-64E
- 2 Grayscale cameras, 1.4 Megapixels: Point Grey Flea 2 (FL2-14S3M-C)
- 2 Color cameras, 1.4 Megapixels: Point Grey Flea 2 (FL2-14S3C-C)
- 4 Varifocal lenses, 4-8 mm: Edmund Optics NT59-917
센서 구성에서 알 수 있다시피, KITTI Dataset은 단순히 카메라 데이터만을 포함하고 있지는 않다. GPS, IMU 정보와 LiDAR Pointcloud 정보도 내장하고 있다. 그렇지만 본 프로젝트에서는 카메라 데이터만 이용할 예정이다.
다만 신호등에 대한 라벨링 정보가 없어 신호등에 대한 학습이 제한된다는 단점이 있다.

KITTI 홈페이지에 간단한 가입을 마친 후에서 ‘Object’ 탭 내의 ‘left color images of object data set‘과 ‘training labels of object data set’ 을 다운로드 받는다.
이후 ‘training labels of object data set‘의 압축파일 내의 ‘training’-‘label_2’ 폴더가 ‘left color images of object data set‘의 ‘training’ 폴더 내에 압축 해제되도록 한다.

기본적인 Dataset 구성은 다음과 같다.
- Training Image : 7,481 images (Resolution : 1242 * 375) / 7,481 labels
- Testing image : 7,518 images -> label이 없으므로 사용하지 않을 예정
- Classification : [‘Cyclist’, ‘DontCare’, ‘Misc’, ‘Person_sitting’, ‘Tram’, ‘Truck’, ‘Van’, ‘car’, ‘person’] - 9개 분류
2.2. nuScenes Dataset
현대자동차그룹과 앱티브(Aptiv)의 합작사인 ‘모셔널(Motional)’이 구축한 자율주행 개발을 위한 Dataset으로 360도 감지를 위한 6대의 카메라와 5대의 레이더, 1대의 LiDAR, IMU, GPS를 통해 수집된 데이터이다. 즉 자율주행 차량에 필요한 모든 센서를 부착 후 수집하여, 완전한 자율주행 차량 개발에 응용이 가능하며, 1,400,000의 카메라 이미지와 390,000 라이다 포인트를 갖고 있으며, 데이터 수집을 위한 운행은 보스턴과 싱가포르에서 수행되었다. 23개의 객체 분류를 갖고있다.
2.3. Waymo Dataset
Waymo Dataset은 CVPR 2019에서 공개된 연구 목적 비상업용 Dataset으로 Motion Dataset과 Perception Dataset으로 나누어 제공되며, 자율주행 자동차의 인지분야와 관련된 데이터는 Perception Dataset이다.
이 Dataset은 Waymo의 자율주행 차량이 1950개 주행 구간에서 수집한 지역별, 시간별, 날씨별 데이터를 포함하고 있으며 각 구간은 10Hz, 20초의 연속주행 데이터를 포함하고 있다. 즉 20,000,000개 이상의 프레임 데이터와 시간 환산 시 500시간이 넘는 데이터이다. 또한 전방 카메라 데이터 외에도 5개의 라이다(LiDAR, 중거리 LiDAR 1개, 단거리 LiDAR 4개) 데이터 등도 포함하고 있으며 4개의 Class 정보(Vehicles, Pedestrians, Cyclists, Signs)와 1000개의 카메라 Segments 데이터를 포함하고 있다.
2.4. BDD100K
UC 버클리 인공지능 연구실(BAIR)에서 공개한 Dataset으로 40초의 비디오 시퀀스, 720px 해상도, 30 fps의 동영상으로 취득된 100,000개의 비디오 시퀀스로 구성된다. 해당 Dataset에는 다양한 날씨 조건은 물론, GPS 정보, IMU 정보, 시간 정보도 포함되어 있다. 또한 차선 및 주행 가능 영역에 대한 라벨링이 되어있다. 그리고 버스, 신호등, 교통 표지판, 사람, 자전거, 트럭, 자동차 등의 정보가 담긴 100,000개의 이미지에 라벨링이 완료된 2D Bounding Box가 포함되어 있다.
BDD100K는 이와 같은 정보를 통해 물체 검출, 세그먼테이션, 운전 가능 지역, 차선 검출 등의 Task 수행이 가능하다.
3. Methodology
[Computing Environment]
- OS : Windows 10 Pro 21H2 / WSL2 Ubuntu
- CPU : Intel(R) Core(TM) i7-9700K CPU @ 3.60GHz
- RAM : 32GB
- GPU : NVIDIA GeForce GTX970 4GB (Driver version - 497.09, CUDA version - 11.5)
- Capture Board : AVerMedia GC553
- Anaconda Command line client (version 1.9.0)
F 드라이브 내에 project 폴더를 만들어서 해당 프로젝트를 진행하였으며, Anaconda를 이용하여 가상환경을 설정하여 진행하였음
패키지 호환성을 위하여 Python 버전은 3.8버전을 설치할 것을 권장
1
conda create -n 'env_name' python=3.8
3.1. YOLOv5(You Only Look Once)
https://github.com/ultralytics/yolov5
YOLO는 ‘You Only Look Once’의 약자로 2016년 Joseph Redmon이 CVPR에서 발표한 ‘You Only Look Once: Unified, Real-Time Object Detection’ 객체 탐지(Object Detection) 딥러닝 모델이다.
해당 논문 발표 당시에는 대표적인 객체 탐지 기법으로 R-CNN(Region with Convolutional Neural Network) 계열(R-CNN, Fast R-CNN, Faster R-CNN 등)과 DPM(Deoformable Part Models) 등이 존재하고 있었다. 그러나 해당 기법들의 정확도는 좋았으나, 객체 탐지를 실시간으로 하기에는 너무 느렸다. Faster R-CNN의 경우에도 7fps가 최대 속도였다.

이러한 기법들은 2단계로 이미지를 처리하기 때문이었다. 즉 이미지 입력이 들어오면 객체가 있을 것으로 추정되는 영역 ROI(Region Of Interest)를 추출한 이후, 다음 단계에서 ROI들은 분류기(Classifier)에 의해 객체별로 분류가 이루어지는 구조였다.

그러나 YOLO는 다르다. YOLO는 단 한 단계의 구조로 네트워크가 작동하는데, 즉 이미지의 특징(Feature) 추출, 객체(Object)의 위치 파악, 객체 분류(Classification)이 한 번에 수행되므로 앞서 언급된 구조들에 비해서 정확도는 조금 떨어지지만 처리 속도가 매우 빠르고 간단하다.
즉, YOLO의 주요한 특징은 크게 다음과 같이 3가지로 설명될 수 있다.
You Only Look Once
YOLO는 ROI등의 기법 사용 없이 이미지 전체를 단 한번만 본다.
Unified Detection
다른 객체 탐지 모델 들은 다양한 전처리 모델과 인공 신경망을 결합해서 사용하지만, YOLO는 단 하나의 인공신경망에서 이를 전부 처리한다. 이런 특징 때문에 YOLO가 다른 모델보다 간단해 보인다.
Real-Time Object Detection
2단계의 객체 탐지 모델들에 비해서 매우 빠르게 객체 탐지가 가능하기 때문에 실시간으로 사용이 가능하다.
가장 초창기 YOLOv1의 구조는 다음과 같다.

전체적인 네트워크 신경망 구조는 총 24개의 합성곱 레이어(Convolutional Layer)와 2개의 Fully-Connected Layer를 사용하고 있다.
Pre-trained Network
위의 이미지 중 좌측부터 6개의 Layer Box는 Pre-trained Network로 GooLeNet을 사용해 ImageNet 1000-class Dataset을 사전에 학습하고 이를 Fine-tuning한 네트워크이다. 이 사전학습 네트워크는 총 20개의 합성곱 레이어(Convolutional Layer)로 이루어져 있다. Fine-tuning 과정에서의 특이한 점은 ImageNet의 이미지는 224*224의 크기를 갖지만 이미지를 의도적으로 2배 키워 해당 데이터를 학습에 사용하였다.
Reduction Layer
YOLO는 1x1의 합성곱 레이어(Convolutional Layer)를 교대로 적용하여 이를 이용하여 Feature Space를 축소시켜(reduce), 계산 속도를 향상시켰다.
Training Layer
2개의 Fully-Connected Layer로 이루어져 있으며, 앞선 네트워크에서 학습한 Feature를 토대로 Class probability와 Bounding Box의 위치를 학습하고 예측한다. YOLO의 최종 출력은 7x7x30의 예측 텐서(prediction tensors)로 나온다.
여기까지가 YOLO에 대한 간략하면서도 전체적인 설명이었다.
이번 프로젝트에서 사용할 YOLOv5는 이러한 YOLO의 5번째 버전이라는 뜻이다. 다만, 기존의 버전들과의 차이점이 있다면 YOLOv5는 YOLO를 처음 고안한 Joseph Redmon에 의해 탄생된 것이 아니라는 점이다. YOLOv5는 Glenn Jocher가 만든 것으로 속도 측면에서는 기존의 YOLO 이외에도 다른 객체 탐지 모델에 비해 탐지 속도가 매우 빠르다는 점이다.
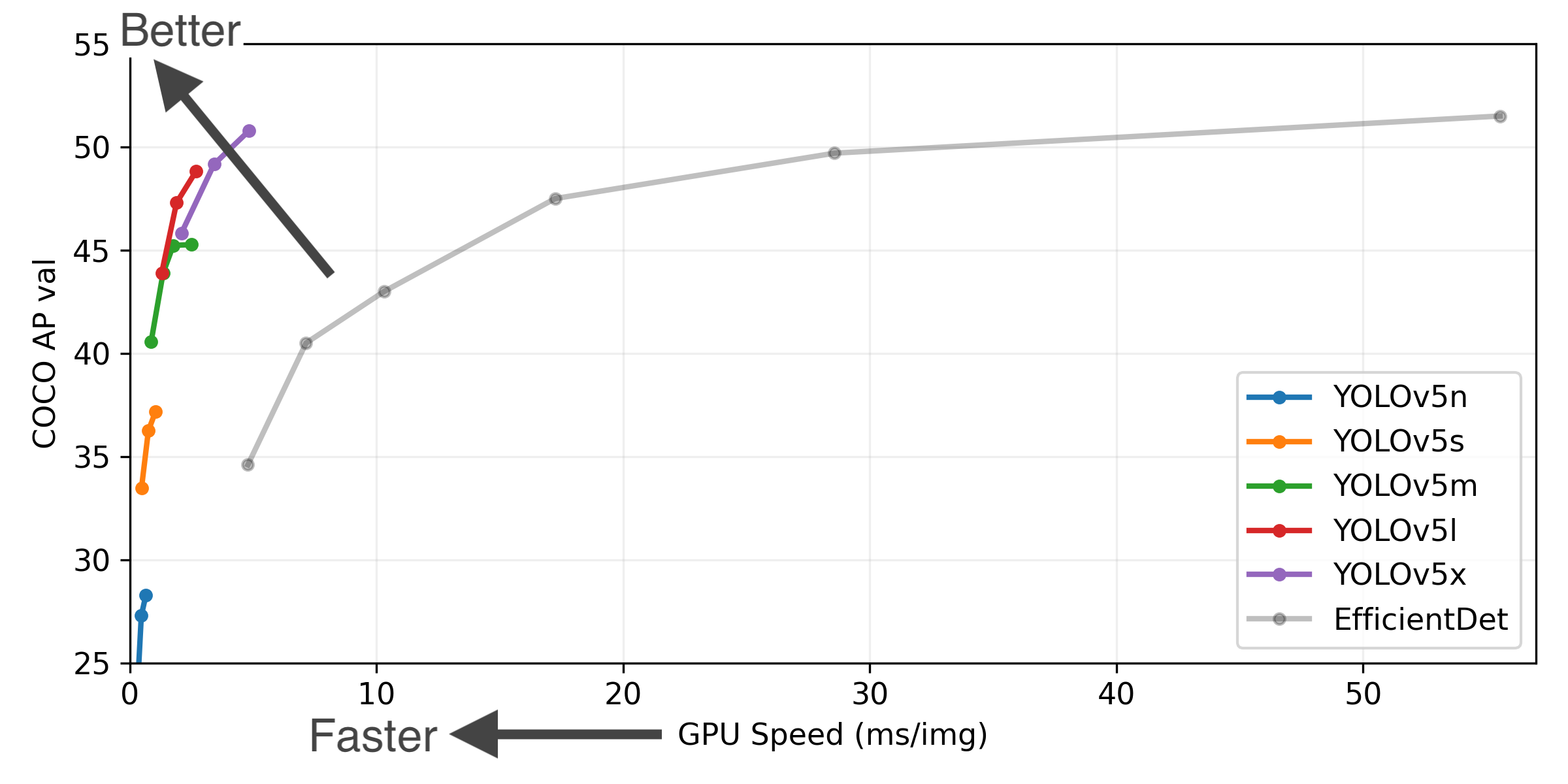
YOLOv5가 객체 탐지(Object Detection) 모델 중에 매우 빠른 편에 속하므로, 실시간 요소에 적용하기 적합하며, 이러한 이유로 본 프로젝트, 즉 자율주행의 객체 탐지 모델에 사용하기 유리할 것으로 판단되어 YOLOv5를 본 프로젝트에서 사용하기로 하였다.
[YOLOv5 Setting]
1 . 우선 F 드라이브 내에 본 프로젝트 파일을 정리하고 저장할 폴더 ‘project’를 생성한 후, Windows PowerShell을 이용하여 해당 폴더로 이동한다.
1
2
cd F:\project
pwd
1
2
3
Path
----
F:\project
2 . 이후 git 명령어를 이용하여 Github의 Yolov5 Repository를 우리가 사용할 폴더에 git clone 해주도록 한다.
1
git clone https://github.com/ultralytics/yolov5
1
2
3
4
5
Cloning into 'yolov5'...
remote: Enumerating objects: 10222, done.
remote: Total 10222 (delta 0), reused 0 (delta 0), pack-reused 10222
Receiving objects: 100% (10222/10222), 10.49 MiB | 9.56 MiB/s, done.
Resolving deltas: 100% (7066/7066), done.
3 . 이후 project 폴더를 확인해보면 ‘yolov5’ 폴더가 생성된 것을 확인할 수 있다. 그리고 해당 폴더 내에 어떠한 파일들이 있는지 확인해보자.
1
ls
1
2
3
4
5
6
디렉터리: F:\project
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2021-12-16 오후 2:09 yolov5
1
2
cd yolov5
ls
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
디렉터리: F:\project\yolov5
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 2021-12-16 오후 2:09 .github
d----- 2021-12-16 오후 2:09 data
d----- 2021-12-16 오후 2:09 models
d----- 2021-12-16 오후 2:09 utils
-a---- 2021-12-16 오후 2:09 3905 .dockerignore
-a---- 2021-12-16 오후 2:09 77 .gitattributes
-a---- 2021-12-16 오후 2:09 4219 .gitignore
-a---- 2021-12-16 오후 2:09 1619 .pre-commit-config.yaml
-a---- 2021-12-16 오후 2:09 5085 CONTRIBUTING.md
-a---- 2021-12-16 오후 2:09 12603 detect.py
-a---- 2021-12-16 오후 2:09 2227 Dockerfile
-a---- 2021-12-16 오후 2:09 21073 export.py
-a---- 2021-12-16 오후 2:09 6524 hubconf.py
-a---- 2021-12-16 오후 2:09 35801 LICENSE
-a---- 2021-12-16 오후 2:09 15038 README.md
-a---- 2021-12-16 오후 2:09 928 requirements.txt
-a---- 2021-12-16 오후 2:09 974 setup.cfg
-a---- 2021-12-16 오후 2:09 33294 train.py
-a---- 2021-12-16 오후 2:09 58110 tutorial.ipynb
-a---- 2021-12-16 오후 2:09 18365 val.py
4 . 이제 Yolov5를 원활히 구동하기 위해서는 YOLOv5 작동에 필요한 라이브러리를 설치해야 한다. 이러한 의존성 패키지 관련 정보는 requirments.txt에 정리되어 있으므로 해당 파일을 열어서 확인해보자.
1
cat requirements.txt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# Extras --------------------------------------
# albumentations>=1.0.3
# Cython # for pycocotools https://github.com/cocodataset/cocoapi/issues/172
# pycocotools>=2.0 # COCO mAP
# roboflow
thop # FLOPs computation
5 . 해당 requirements.txt 파일에 의존성 패키지에 관한 정보가 정리되어 있고, 해당 파일 내에 서술된 것처럼 pip install 명령어 실행을 통하여 YOLOv5 작동에 필요한 라이브러리를 받을 수 있다.
1
pip install -r requirements.txt
여기까지 문제없이 잘 이루어졌다면, 본격적으로 YOLOv5의 사용 준비는 모두 끝난 것이다.
3.2. Dataset Pre-Processing
자율주행 자동차의 이미지 검출 모델 학습에 사용되는 Dataset들은 모두 통일된 Format으로 존재하는 것이 아니라, 객체가 존재하는 곳을 표현하는 Bounding Box의 좌표값에 대한 Labeling 방법, 그리고 객체의 종류를 정리해놓은 Annotation의 방법이 서로 다르기 때문에 사용할 Dataset의 Format을 확인하여 Yolov5의 학습에 적합한 형태로 가공해주어야 한다.
YOLO Dataset Format
YOLO Format의 경우 test, train, valid 폴더 내에 각각의 images, labels 폴더가 정의되며, images 폴더 내의 image 1개와 labels 폴더 내의 annotation 정보를 담고 있는 txt 파일 1개와 1대1 매칭된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
Dataset ├── test │ ├── images │ │ ├── test_1.jpg │ │ ├── test_2.jpg │ │ ├── ... │ │ └── test_n.jpg │ └── labels │ ├── test_1.txt │ ├── test_2.txt │ ├── ... │ └── test_n.txt ├── train │ ├── images │ │ ├── train_1.jpg │ │ ├── train_2.jpg │ │ ├── ... │ │ └── train_n.jpg │ └── labels │ ├── train_1.txt │ ├── train_2.txt │ ├── ... │ └── train_n.txt ├── valid │ ├── images │ │ ├── valid_1.jpg │ │ ├── valid_2.jpg │ │ ├── ... │ │ └── valid_n.jpg │ └── labels │ ├── valid_1.txt │ ├── valid_2.txt │ ├── ... │ └── valid_n.txt │ # YOLOv5 학습 모델에게 Train, Valid 폴더의 위치 정보와 Class의 개수, Class의 이름 정보 포함 └── data.yaml
data.yaml파일을 살펴보면 다음과 같이 표현되어 있다. 즉, YOLO를 학습시키려면data.yaml을 형식에 맞게 생성해주어야 한다.1
cat data.yaml
1 2 3 4 5
train: F:/project/yolov5/Dataset/KITTI_YOLOv5/train/images val: F:/project/yolov5/Dataset/KITTI_YOLOv5/valid/images nc: 9 names: ['Cyclist', 'DontCare', 'Misc', 'Person_sitting', 'Tram', 'Truck', 'Van', 'car', 'person']
KITTI Dataset Format
우리가 사용할 KITTI Dataset도 YOLO와 같은 방식으로 image와 txt 파일의 폴더별 분리 및 1대1일 매칭 구조이지만 annotation 방법이 서로 다르다.
VOC Dataset Format
VOC Format의 경우 각 이미지 파일에 맞는 Annotation(Label)이 xml 파일 형태로 1대1 대응된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Dataset ├── test │ ├── test_1.jpg │ ├── test_1.xml │ ├── test_2.jpg │ ├── test_2.xml │ ├── ... │ ├── test_n.jpg │ └── test_n.xml ├── train │ ├── train_1.jpg │ ├── train_1.xml │ ├── train_2.jpg │ ├── train_2.xml │ ├── ... │ ├── train_n.jpg │ └── train_n.xml └── valid ├── valid_1.jpg ├── valid_1.xml ├── valid_2.jpg ├── valid_2.xml ├── ... ├── valid_2.jpg └── valid_n.xmlCOCO Dataset Format
COCO Format의 경우 Annotation(Label)이 하나의 JSON 파일에 정리되어 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Dataset ├── test │ ├── test_1.jpg │ ├── test_2.jpg │ ├── ... │ ├── test_n.jpg │ └── annotation_test.json # test_1.jpg ~ test_n.jpg의 모든 annotation 정보 포함 ├── train │ ├── train_1.jpg │ ├── train_2.jpg │ ├── ... │ └── annotation_train.json # train_1.jpg ~ train_n.jpg의 모든 annotation 정보 포함 └── valid ├── valid_1.jpg ├── valid_2.jpg ├── ... └── annotation_valid.json # valid_1.jpg ~ test_n.jpg의 모든 annotation 정보 포함
또한, 각각의 Format들은 Bounding Box의 Annotation에 사용하는 Bounding Box의 좌표값도 서로 다르다.

이렇게 서로 다른 Dataset의 Directory 구조와 Annotation 방법, 확장자를 YOLO 형식에 맞게 바꿔주는 것은 꽤 고단한 일이다.
KITTI Format의 Image Size와 Bounding Box의 Size를 입력으로 받는다면 YOLO 형식으로 다음과 같이 바꿔줄 수 있을 것이다.
1
2
3
4
5
6
7
8
9
10
def convert_boundig_box_coordinate(img_size, box_size):
x_center = (box_size[0] + box_size[1])/2.0
y_center = (box_size[2] + box_size[3])/2.0
width = box_size[1] - box_size[0]
height = box_size[3] - box_size[2]
x_norm = x_center./img_size[0]
y_norm = y_center./img_size[1]
w_norm = width./img_size[0]
h_norm = height./img_size[1]
return(x_norm, y_norm, w_norm, h_norm)
이렇게 직접 코딩으로 진행해도 되는 일이지만, 단순 좌표 계산 이외에도 파일 형식 변환, Annotation List 확인 등 많은 작업이 필요하고 수고가 따르는 일이다.
그러나 다행이다. 이러한 작업을 수월하게 도와주는 사이트인 ‘Roboflow‘가 존재한다. 해당 사이트는 다양한 종류의 Dataset Format을 다른 종류의 Dataset Format으로 바꿔줄 수 있는 기능을 제공한다. YOLOv5 사용에서도 해당 사이트를 이용해서 Dataset Format을 바꾸는 것을 권장하고 있다.
해당 사이트에서 우리가 갖고 있는 KITTI Dataset을 YOLO Format에 맞게 변형(Transform)하도록 한다.
1 . Roboflow 접속 후 회원가입하여 로그인한다.

2 . Roboflow 로그인 이후, 기존 Workspace 내에서 새로운 Project를 생성해준다.

3 . Project 설정을 완료한다.

4 . 다운로드 받아두었던 Dataset을 Roboflow에 업로드한다. (training 폴더를 업로드)
- test 폴더 내에는 annotation 정보가 없으므로 학습에 쓸모가 없다.



5 . 업로드가 완료되면 Annotation 과정에서의 오류 처리 과정이 등장하며, 큰 문제가 없는지 확인한다.

6 . 이후 업로드 된 이미지들의 썸네일을 확인할 수 있으며, 추가적인 Data 추가 등이 가능하다. 우리는 더 추가할 Data가 없으므로 ‘Finish Uploading’을 눌러 업로드 과정을 마치도록 한다.

7 . 이후 단계는 Train/Valid/Test Data의 양을 조정하는 단계로 필요한만큼 설정한다.

8 . Split 설정 완료 후 Format이 변환된 Dataset이 업로드 되며, 잠시 기다린다.

9 . 업로드가 완료된 이후 Dataset에 대한 몇 가지 설정을 진행할 수 있다.

Resize
Image의 Size를 조절한다. YOLOv5(s, m, l 등) 모델에서는 학습에 사용가능한 최대 이미지 크기는 640 x 640 (1대1 비율)이며, YOLOv5(s6, m6, l6) 모델에서는 학습에 사용가능한 최대 이미지 크기는 1280 x 1280 (1대1 비율)이다. 이후 설명하겠지만 우리는 YOLOv5s 모델을 사용할 것이고, 학습에 사용하는 이미지의 크기가 클수록 학습의 효과는 올라가지만, 학습 시간이 오래걸리므로 하드웨어 환경을 고려하여 기본값 (416 x 416)을 사용한다.
또한, 이미지의 Crop이나 Letterbox를 넣어 기존 이미지 비율을 맞추는 것은 정보의 손상, 실질 이미지의 크기 저하로 학습에 안좋은 효과가 발생할 수 있으므로 기존 이미지의 비율은 망가지더라도 Annotation 정보가 모두 살아있도록 Stretch를 사용한다.
Add Step(Preprocessing)
![]()
이미지의 특성을 강화하기 위한 전처리 과정으로 흑백처리, 대비 조절 등의 옵션이 있지만, 우리는 사용하지 않는다.

10 . Augmentation Step은 Bounding Box에 대한 전처리 과정으로 Bounding Box 영역에 해당하는 곳을 흑백 처리하거나, 잘라내거나 하는 등의 변형을 줄 수 있으나 우리는 사용하지 않는다.


11 . Generate Step에서 ‘Generate’ 버튼을 눌러 다음 단계로 진행한다.

12 . 최종적으로 Dataset의 간략한 정보가 나온다. ‘Export’를 눌러 Dataset을 내려받는다.

13 . Dataset을 어떤 Format으로 출력할지 선택해준다. 우리는 ‘YOLO v5 PyTorch’를 선택해준다. 이후 Roboflow API를 이용하여 터미널에서 바로 변환된 Dataset을 받아도 되지만, 클라우드 환경이나 Google Colaboratory 등에서 이점이 많으나, 로컬 환경에서 진행하고 있으므로 ZIP 파일 형태로 다운로드 받는다.

- Dataset 폴더는 yolov5 폴더 내에 위치하는 것이 작업에 편리하다.
14 . 다운로드 받은 Dataset 내부에 yaml 파일의 정보를 다음과 같이 수정해주어야 한다.
1
cat data.yaml
1
2
3
4
5
train: ../train/images
val: ../valid/images
nc: 9
names: ['Cyclist', 'DontCare', 'Misc', 'Person_sitting', 'Tram', 'Truck', 'Van', 'car', 'person']
train: ../train/images 과 val: ../valid/images 의 주소를 명확하게 하기위해 Dataset을 저장한 경로를 기입한다.
예시
train: F:/project/yolov5/Dataset/KITTI_YOLOv5/train/images
val: F:/project/yolov5/Dataset/KITTI_YOLOv5/valid/images
이로써 Dataset 전처리 과정이 모두 끝났으며, 본격적으로 학습을 시작할 수 있다.
3.3. Dataset Training
이제 본격적으로 YOLOv5을 Preprocessing이 완료된 Dataset을 통해 학습을 진행해주면 된다.
학습에 앞서 YOLOv5에 맞는 torch/PyTorch, torchvision, torchaudio, cudatoolkit을 설치해주어야 한다.
몇 번의 시행착오 결과, cudatoolkit=11.3버전이 잘 작동하지 않았으며, 가장 잘 맞는 세팅은 Python 3.8.12기준 Pytorch(torch) = 1.10.0, torchvision = 0.11.1, torchaudio = 0.10.0, cudatoolkit = 10.2 버전으로 파악되었으므로, 패키지 버전을 맞춰준다.
1
2
3
4
5
# conda를 이용한 설치
conda install pytorch=1.10.0 torchvision=0.11.1 torchaudio=0.10.0 cudatoolkit=10.2 -c pytorch
# pypi를 이용한 설치
pip3 install torch==1.10.0+cu102 torchvision==0.11.1+cu102 torchaudio===0.10.0+cu102 -f https://download.pytorch.org/whl/cu102/torch_stable.html

우리는 자율주행 자동차의 상황을 가정하여, 정확도도 중요하지만 더 중요한 것은 객체 검출의 빠른 응답성이며, 컴퓨팅 환경의 특성상 큰 가중치 모델(ex. YOLOv5l, YOLOv5x) 등의 학습에 어려움이 있으므로, YOLOv5s pre-trained model을 학습 가중치로 사용한다.
성능은 YOLOv5x, YOLOv5l, YOLOv5m, YOLOv5s 순으로 좋으며, FPS는 역순으로 빠르다.
Epoch = 25 / Batch = 16 으로 학습을 진행해본다.
1
python train.py --img 416 --batch 16 --epochs 25 --data 'Dataset/KITTI_YOLOv5/data.yaml' --weights yolov5s.pt --cache
–img : Dataset image의 size (1:1 비율 기준)
–batch : 학습에 사용할 batch의 사이즈 (Iteration 횟수 = Dataset Image 개수 / Batch Size)
–epochs : 학습에 사용할 Epochs의 횟수
–data : Dataset의 정보(YOLO Format)가 저장된 YAML 파일의 위치
–cfg : 모델의 YAML 파일의 위치
–weights : 학습에 사용할 가중치 모델 (custom model 혹은 pre-trained model; yolov5s.pt, yolov5l.pt 등)
–device : 학습에 사용할 하드웨어 선정 CPU(cpu) / GPU(0, 1, 2, 3)
Nvidia CUDA 가속 가능 하드웨어 사용시 GPU 사용 추천
–name : 학습 정보를 ‘runs’ 폴더에 저장할 때 사용할 이름 (default = exp, exp2, exp3, …)
–resume : 학습을 재개를 명령하는 변수, 학습 과정 중 중간에 종료된 경우 해당 명령어 사용시 마지막으로 시행했던 epoch부터 다시 시작하며 weights는 ‘last.pt’ 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
train: weights=yolov5s.pt, cfg=, data=Dataset/KITTI_YOLOv5/data.yaml, hyp=data\hyps\hyp.scratch.yaml, epochs=25, batch_size=16, imgsz=416, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=ram, image_weights=False, device=, multi_scale=False, single_cls=False, adam=False, sync_bn=False, workers=8, project=runs\train, name=exp, exist_ok=False, quad=False, linear_lr=False, label_smoothing=0.0, patience=100, freeze=0, save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: remote: Enumerating objects: 4, done.
remote: Counting objects: 100% (4/4), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 4 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (4/4), 10.30 KiB | 263.00 KiB/s, done.
From https://github.com/ultralytics/yolov5
* [new branch] fix/jit -> origin/fix/jit
up to date with https://github.com/ultralytics/yolov5
YOLOv5 v6.0-147-g628817d torch 1.10.0+cu102 CUDA:0 (NVIDIA GeForce GTX 970, 4096MiB)
hyperparameters: lr0=0.01, lrf=0.1, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=9
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 37758 models.yolo.Detect [9, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 270 layers, 7043902 parameters, 7043902 gradients, 15.9 GFLOPs
Transferred 343/349 items from yolov5s.pt
Scaled weight_decay = 0.0005
optimizer: SGD with parameter groups 57 weight, 60 weight (no decay), 60 bias
train: Scanning 'F:\project\yolov5\Dataset\KITTI_YOLOv5\train\labels' images and labels...5237 found, 0 missing, 0 empt
train: WARNING: F:\project\yolov5\Dataset\KITTI_YOLOv5\train\images\000005_png.rf.281f637fc5adac2f716ffd1c902f8cf2.jpg: 1 duplicate labels removed
train: WARNING: Cache directory F:\project\yolov5\Dataset\KITTI_YOLOv5\train is not writeable: [WinError 183] 파일이 이
미 있으므로 만들 수 없습니다: 'F:\\project\\yolov5\\Dataset\\KITTI_YOLOv5\\train\\labels.cache.npy' -> 'F:\\project\\yolov5\\Dataset\\KITTI_YOLOv5\\train\\labels.cache'
train: Caching images (2.7GB ram): 100%|█████████████████████████████████████████| 5237/5237 [00:01<00:00, 3896.66it/s]
val: Scanning 'F:\project\yolov5\Dataset\KITTI_YOLOv5\valid\labels.cache' images and labels... 1496 found, 0 missing, 0
val: Caching images (0.8GB ram): 100%|███████████████████████████████████████████| 1496/1496 [00:00<00:00, 2765.24it/s]
module 'signal' has no attribute 'SIGALRM'
AutoAnchor: 4.44 anchors/target, 0.994 Best Possible Recall (BPR). Current anchors are a good fit to dataset
Image sizes 416 train, 416 val
Using 8 dataloader workers
Logging results to runs\train\exp3
Starting training for 25 epochs...
Epoch gpu_mem box obj cls labels img_size
0/24 1.45G 0.08327 0.03969 0.03698 58 416: 100%|██████████| 328/328 [01:25<00:00, 3.84it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:12<0
all 1496 10764 0.44 0.143 0.109 0.0413
Epoch gpu_mem box obj cls labels img_size
1/24 1.66G 0.06644 0.03281 0.02445 50 416: 100%|██████████| 328/328 [01:20<00:00, 4.10it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.333 0.298 0.19 0.0635
Epoch gpu_mem box obj cls labels img_size
2/24 1.66G 0.06185 0.03187 0.02136 32 416: 100%|██████████| 328/328 [01:19<00:00, 4.12it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:12<0
all 1496 10764 0.557 0.275 0.26 0.105
Epoch gpu_mem box obj cls labels img_size
3/24 1.66G 0.05658 0.03115 0.01924 43 416: 100%|██████████| 328/328 [01:20<00:00, 4.07it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.457 0.398 0.355 0.156
Epoch gpu_mem box obj cls labels img_size
4/24 1.66G 0.05335 0.03152 0.01758 54 416: 100%|██████████| 328/328 [01:21<00:00, 4.04it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.613 0.408 0.395 0.186
Epoch gpu_mem box obj cls labels img_size
5/24 1.66G 0.05056 0.03019 0.01583 49 416: 100%|██████████| 328/328 [01:21<00:00, 4.01it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.659 0.433 0.48 0.221
Epoch gpu_mem box obj cls labels img_size
6/24 1.66G 0.04936 0.02993 0.0149 39 416: 100%|██████████| 328/328 [01:19<00:00, 4.11it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.597 0.511 0.5 0.253
Epoch gpu_mem box obj cls labels img_size
7/24 1.66G 0.04825 0.0297 0.01417 31 416: 100%|██████████| 328/328 [01:19<00:00, 4.12it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.677 0.471 0.514 0.256
Epoch gpu_mem box obj cls labels img_size
8/24 1.66G 0.0474 0.02877 0.01319 83 416: 100%|██████████| 328/328 [01:20<00:00, 4.10it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.562 0.564 0.569 0.286
Epoch gpu_mem box obj cls labels img_size
9/24 1.66G 0.04636 0.0288 0.01297 55 416: 100%|██████████| 328/328 [01:19<00:00, 4.11it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.604 0.588 0.601 0.314
Epoch gpu_mem box obj cls labels img_size
10/24 1.66G 0.04574 0.02843 0.01202 27 416: 100%|██████████| 328/328 [01:19<00:00, 4.12it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.661 0.571 0.602 0.315
Epoch gpu_mem box obj cls labels img_size
11/24 1.66G 0.04516 0.02889 0.01152 63 416: 100%|██████████| 328/328 [01:19<00:00, 4.14it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:10<0
all 1496 10764 0.689 0.575 0.616 0.325
Epoch gpu_mem box obj cls labels img_size
12/24 1.66G 0.04412 0.02824 0.01112 74 416: 100%|██████████| 328/328 [01:20<00:00, 4.10it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.687 0.566 0.623 0.326
Epoch gpu_mem box obj cls labels img_size
13/24 1.66G 0.04371 0.0278 0.01077 71 416: 100%|██████████| 328/328 [01:20<00:00, 4.09it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.752 0.602 0.667 0.358
Epoch gpu_mem box obj cls labels img_size
14/24 1.66G 0.04276 0.02753 0.01013 56 416: 100%|██████████| 328/328 [01:20<00:00, 4.08it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.696 0.624 0.662 0.352
Epoch gpu_mem box obj cls labels img_size
15/24 1.66G 0.04226 0.02746 0.009749 38 416: 100%|██████████| 328/328 [01:20<00:00, 4.07it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:10<0
all 1496 10764 0.715 0.629 0.686 0.38
Epoch gpu_mem box obj cls labels img_size
16/24 1.66G 0.04145 0.02658 0.009636 22 416: 100%|██████████| 328/328 [01:18<00:00, 4.16it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:10<0
all 1496 10764 0.789 0.6 0.692 0.394
Epoch gpu_mem box obj cls labels img_size
17/24 1.66G 0.04121 0.02693 0.00919 45 416: 100%|██████████| 328/328 [01:18<00:00, 4.17it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.739 0.644 0.704 0.4
Epoch gpu_mem box obj cls labels img_size
18/24 1.66G 0.04099 0.02682 0.008838 46 416: 100%|██████████| 328/328 [01:19<00:00, 4.15it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:10<0
all 1496 10764 0.752 0.636 0.702 0.393
Epoch gpu_mem box obj cls labels img_size
19/24 1.66G 0.04045 0.02631 0.008658 78 416: 100%|██████████| 328/328 [01:18<00:00, 4.16it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.759 0.655 0.715 0.412
Epoch gpu_mem box obj cls labels img_size
20/24 1.66G 0.04001 0.02596 0.008381 45 416: 100%|██████████| 328/328 [01:20<00:00, 4.09it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.793 0.65 0.716 0.412
Epoch gpu_mem box obj cls labels img_size
21/24 1.66G 0.03984 0.02614 0.008085 35 416: 100%|██████████| 328/328 [01:19<00:00, 4.10it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:10<0
all 1496 10764 0.731 0.66 0.722 0.419
Epoch gpu_mem box obj cls labels img_size
22/24 1.66G 0.03943 0.02562 0.008116 27 416: 100%|██████████| 328/328 [01:20<00:00, 4.08it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.741 0.681 0.726 0.427
Epoch gpu_mem box obj cls labels img_size
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:11<0
all 1496 10764 0.742 0.686 0.728 0.428
Epoch gpu_mem box obj cls labels img_size
24/24 1.66G 0.03898 0.0255 0.007516 52 416: 100%|██████████| 328/328 [01:18<00:00, 4.16it/
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:10<0
all 1496 10764 0.775 0.67 0.734 0.437
25 epochs completed in 0.639 hours.
Optimizer stripped from runs\train\exp3\weights\last.pt, 14.4MB
Optimizer stripped from runs\train\exp3\weights\best.pt, 14.4MB
Validating runs\train\exp3\weights\best.pt...
Fusing layers...
Model Summary: 213 layers, 7034398 parameters, 0 gradients, 15.9 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:15<0
all 1496 10764 0.775 0.67 0.734 0.438
Cyclist 1496 355 0.84 0.6 0.681 0.346
DontCare 1496 2331 0.536 0.2 0.267 0.0749
Misc 1496 186 0.779 0.699 0.756 0.442
Person_sitting 1496 22 0.615 0.437 0.527 0.235
Tram 1496 130 0.788 0.915 0.939 0.549
Truck 1496 228 0.914 0.93 0.967 0.698
Van 1496 590 0.867 0.853 0.906 0.631
car 1496 5948 0.852 0.901 0.942 0.688
person 1496 974 0.787 0.498 0.62 0.272
Results saved to runs\train\exp3
따로 --name 값을 설정해주지 않았으므로 학습 로그와 학습된 weights 파일 best.pt와 마지막 epoch에 의한 wieghts 계산값 last.pt는 yolov5\runs\train\exp 경로에 저장된다. 학습에 소요된 시간은 0.639 시간으로 측정되었다.
epoch = 25
1
python train.py --img 416 --batch 16 --epochs 25 --data 'Dataset/KITTI_YOLOv5/data.yaml' --weights yolov5s.pt --cache
1 2 3 4 5 6 7 8 9 10 11 12
Model Summary: 213 layers, 7034398 parameters, 0 gradients, 15.9 GFLOPs Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:15<0 all 1496 10764 0.775 0.67 0.734 0.438 Cyclist 1496 355 0.84 0.6 0.681 0.346 DontCare 1496 2331 0.536 0.2 0.267 0.0749 Misc 1496 186 0.779 0.699 0.756 0.442 Person_sitting 1496 22 0.615 0.437 0.527 0.235 Tram 1496 130 0.788 0.915 0.939 0.549 Truck 1496 228 0.914 0.93 0.967 0.698 Van 1496 590 0.867 0.853 0.906 0.631 car 1496 5948 0.852 0.901 0.942 0.688 person 1496 974 0.787 0.498 0.62 0.272- 학습 소요시간 : 0.639 hrs
이후 epoch = 50, epoch = 100, epoch = 100 without pre-trained weights 학습을 진행하였다.
epoch = 50
1
python train.py --img 416 --batch 16 --epochs 50 --data 'Dataset/KITTI_YOLOv5/data.yaml' --weights yolov5s.pt --cache
1 2 3 4 5 6 7 8 9 10 11 12
Model Summary: 213 layers, 7034398 parameters, 0 gradients, 15.9 GFLOPs Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:15<0 all 1496 10764 0.874 0.692 0.772 0.486 Cyclist 1496 355 0.873 0.656 0.748 0.403 DontCare 1496 2331 0.612 0.167 0.294 0.0861 Misc 1496 186 0.862 0.801 0.864 0.541 Person_sitting 1496 22 0.834 0.455 0.518 0.234 Tram 1496 130 0.976 0.933 0.977 0.653 Truck 1496 228 0.973 0.95 0.972 0.742 Van 1496 590 0.927 0.86 0.934 0.677 car 1496 5948 0.923 0.895 0.954 0.724 person 1496 974 0.883 0.513 0.691 0.314- 학습 소요시간 : 1.251 hrs
epoch = 100
1
python train.py --img 416 --batch 16 --epochs 100 --data 'Dataset/KITTI_YOLOv5/data.yaml' --weights yolov5s.pt --cache
1 2 3 4 5 6 7 8 9 10 11 12
Model Summary: 213 layers, 7034398 parameters, 0 gradients, 15.9 GFLOPs Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:16<0 all 1496 10764 0.781 0.776 0.806 0.528 Cyclist 1496 355 0.777 0.746 0.784 0.453 DontCare 1496 2331 0.478 0.363 0.341 0.104 Misc 1496 186 0.755 0.871 0.907 0.591 Person_sitting 1496 22 0.65 0.591 0.64 0.298 Tram 1496 130 0.912 0.953 0.971 0.694 Truck 1496 228 0.941 0.956 0.979 0.782 Van 1496 590 0.895 0.939 0.961 0.733 car 1496 5948 0.878 0.937 0.964 0.757 person 1496 974 0.742 0.629 0.708 0.335- 학습 소요시간 : 2.498 hrs
epoch = 100 without pre-trained weights
1
python train.py --img 416 --batch 16 --epochs 100 --data 'Dataset/KITTI_YOLOv5/data.yaml' --cache
1 2 3 4 5 6 7 8 9 10 11 12
Model Summary: 213 layers, 7034398 parameters, 0 gradients, 15.9 GFLOPs Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 47/47 [00:15<0 all 1496 10764 0.806 0.765 0.806 0.526 Cyclist 1496 355 0.851 0.721 0.787 0.451 DontCare 1496 2331 0.513 0.333 0.337 0.0997 Misc 1496 186 0.816 0.879 0.909 0.594 Person_sitting 1496 22 0.63 0.545 0.608 0.286 Tram 1496 130 0.915 0.962 0.984 0.687 Truck 1496 228 0.946 0.956 0.978 0.778 Van 1496 590 0.907 0.942 0.964 0.739 car 1496 5948 0.891 0.93 0.963 0.756 person 1496 974 0.787 0.619 0.723 0.341- 학습 소요시간 : 2.529 hrs
3.4. Inference(Detection)
1
python detect.py --weights runs/train/exp/weights/best.pt --source 1
epoch=100의 값이 runs/train/exp/weights/best.pt에 위치하므로 해당 값을 사용
하드웨어 부하를 줄이기 위하여 외장 캡쳐보드를 이용하여 Game Graphics Real-time Capture 하여 Detection 진행
--source 1 : 외장 캡쳐보드의 장치 주소
- –weights : Detection에 사용한 Weights 값 (학습으로 얻은
best.pt혹은 pre-trained modelyolov5l.pt등 사용 가능) - –conf : Bounding Box를 그리는 기준이 되는 Threshold 값으로 0 ~ 1 사이의 값
- –source : Detection을 시행할 Image, Video 등의 경로
--source 0 # webcam--source 1 # capture board, etc...--source image.jpg # image--source video.mp4 # video--source path/ # Whole directory--source path/*.jpg # glob--source 'https://youtu.be/something' # Youtube--source 'rtsp://something.com/video.mp4' # RTSP, RTMP, HTTP Stream
- –img : Detection Source(Image or Video) Size (기본값: 640)
- –classes : 원하는 클래스만 Filtering. (e.x.
--class 0 2 3) - –name : Detection 결과를 저장할 이름
- –exist-ok : 기존 파일이 존재하면 덮어씌운다.
Real-time Vehicle Detection @ Froza Horizon 5
epoch=100의 훈련으로 얻은 weights를 이용하여 ‘Forza Horizon 5’에서 Detection 진행
Real-Time Inference 결과 YOLOv5의 특성상 정확하지는 않아도 빠르게 검출이 진행되는 모습을 확인할 수 있었다.
Real-time Vehicle Detection @ GTA 5
epoch=100의 훈련으로 얻은 weights를 이용하여 ‘GTA 5’에서 Detection 진행
Real-Time Inference 결과 Forza Horizon 5 게임에 비해 정확도와 검출 속도가 다소 안좋아진 모습을 확인할 수 있었다.
3.5. Detection with Pre-trained Model(YOLOv5s)
우리가 사용한 KITTI Dataset으로 학습한 모델 이외에 기존의 COCO Dataset으로 pre-trained 된 YOLOv5s를 COCO Label을 이용하여 Object Detection을 시행해보았다.
Object Detection with pre-trained weights(YOLOv5s.pt) @ Froza Horizon 5
Object Detection with pre-trained weights(YOLOv5s.pt) @ GTA 5
두 게임 모두 대체적으로 Custom Training없이 Pre-trained Model(YOLOv5s)만을 사용한 모델이 KITTI Dataset으로 학습한 Custom 모델에 비해서 차량 검출 정확도가 높게 보였다. 다만 기타 사물에 대해서는 오검출 요소도 가끔 존재하였다. 이는 YOLOv5s의 학습 단계에서 COCO Dataset의 데이터량과 학습 반복의 효과로 인해 우리의 모델보다 더욱 좋은 성능을 내는 것처럼 보인다.
4. Evaluation & Analysis
4.1. Terminology
Precision : 정밀도를 뜻하며, 검출 결과 중 옳게 검출한 비율을 의미한다.
Recall : 재현률을 뜻하며, 입력값이 참일때, 예측이 참으로 나타났는지 확인할때 사용한다. 얼마나 잘 검출하는지를 알 수 있는 척도이다.
Recall과 Precision 예시
사람을 검출하고자 할 때, 사진 속 10명의 사람 중 5명을 검출했다면, recall = 5/10 = 50%
그런데 사람은 5명만 검출했는데 총 20개의 검출 결과가 있었다면, precision = 5/20 = 25%
F1-Score : Recall과 Precision의 조화평균으로, 데이터 불균형 문제를 고려할 수 있는 지표로 사용 가능
AP (Average Precision) : 예측된 결과가 얼마나 정확한지 나타냅니다.
mAP (mean Average Precision) : AP의 평균값으로 합성곱 신경망(Convolutional Neural Network)의 모델 성능 평가의 지표로 사용된다.
4.2. Analysis
- Epoch = 25


- Epoch = 50


- Epoch = 100


- Epoch = 100 (without pretrained weights)


Epoch가 높을수록 학습에 있어서 Validation 과정에서의 Loss가 줄어들고, mAP 지수가 상승하는 모습을 확인할 수 있었다. 또한 Epoch가 같을때, Pre-trained Weights를 사용 유무에 의한 차이는 눈에 띄게 나타나지는 않았지만, 같은 Class (ex. Person_sitting)의 경우 학습 추세가 다르게 나타난 것을 확인할 수 있었다.
또한, epoch에 상관없이 F1-Curve에서 Person과 Person_sitting, 그리고 DontCare의 곡선이 평균 아래에 위치하고 있는 것을 확인하였다.
이를 통해서 해당 데이터들이 다른 데이터들에 비해 데이터가 적은 데이터 불균형이 있는 것은 아닐까 생각을 해보았으며, DontCare의 경우 주행상황에서 고려하지 않아도 될 물체에 대해 동일한 라벨링을 적용하였으므로, 모델로 하여금 일관적인 특징(Feature)를 학습하기 힘들어 다음과 같은 결과가 나오지 않았을까 생각한다.
- Detection Comparison @ Forza Horizon 5
- Detection Comparison @ GTA 5
두 게임 모두 Epochs 횟수 차이에 의한 Detection 매우 큰 차이는 없지만, 특이하게도 Epochs가 낮은 학습일때, 객체를 더욱 빠르고 정확하게 검출하는 모습을 보여주었다. 개인적인 생각으로는 학습이 진행될수록 모델은 보다 실제 자동차에 가까운 특징(Feature)를 갖고 있지 않으면, 게임 내의 자동차를 자동차로 인식하지 않는 것이라고 생각한다.
5. Related Work
인식된 물체 기반으로 제어 및 강화학습으로의 응용성
본 프로젝트에서 진행된 객체 감지 결과물을 이용하여 게임 내에서의 자동차의 자율주행 제어 요소로 활용이 가능할 것으로 예측된다.
(예 : 전방 객체 탐지, 거리 추정 및 충돌 방지 / 차선 검출로 주행 가능 영역 도출 및 운행)
현실의 객체로부터 Dataset을 구축하는 것 이외에도, 현실성 높은 그래픽 엔진을 통해 Dataset 구축
현실의 Dataset이 아닌 고성능 컴퓨터 그래픽을 통해 만들어진 Dataset을 통해서 모델을 학습시킨다면, 현실 세계의 자율주행 자동차 학습에서 사용할 수 있을 것으로 기대된다.
자율주행 자동차의 주변 환경 인지 및 물체 검출
실제 자율주행 자동차에서 어떠한 알고리즘이 메인으로 사용되는지는 정확히 알 수 없지만, 딥러닝 기반의 객체 검출을 이용하므로, YOLO 혹은 R-CNN 네트워크 구조의 일부 변경으로 이러한 성능을 더욱 향상시킬 수 있을 것으로 기대된다.
6. Conclusion & Discussion
본 프로젝트를 진행하면서 YOLO를 이용하여 1단계 객체 검출 모델을 트레이닝하고 객체 감지에 구현해보았다. 성능이 비록 좋다고는 할 수 없지만 빠른 프레임레이트(FPS)로 연산이 수행되는 점이 놀라웠으며, 빠르게 주변 상황을 인지해야하는 실제 차량에서 정확성의 문제만 해결하고 잘 구현하게 된다면 유용할 것이라 생각하였다.
그러나, Real-Time Detection 결과 특정 게임에서는 매우 정확하진 않아도 차량 검출이 빠르게 잘 이뤄졌지만, 그렇지 않은 게임도 있었다. 이렇게 오차가 발생한 원인엔 다음과 같은 이유가 있을 것 같다.
게임 그래픽의 현실과의 차이
우리가 학습에 사용한 Dataset은 실제의 사물 이미지에 기반한 데이터이다. 따라서 YOLOv5 모델이 객체들의 특성(Feature)를 학습할 때, 현실의 물체에서 특성을 학습한 것으로, 컴퓨터 그래픽에 의해 현실성이 다소 떨어지는 그래픽에서의 특성과는 매치가 잘 되지 않았을 수도 있다.
부족한 Epochs
본 프로젝트를 진행하면서 하드웨어의 한계와 시간에 대한 제약으로 최대 Epoch를 100으로 설정하고 진행하였는데, 생각보다 학습이 잘 되지 않은 것 같다.
YOLOv5의 Github Repository를 확인해보니, epoch을 300이상 시행해줘야 모델이 어느정도 성능을 갖는다고 언급 되어있었으며, 300 이상 epoch을 진행해주면서 Overfitting이 발생할때 학습을 중단하는 방식으로 학습을 진행하는 것이 좋다고 적혀있었다. 다음 기회에는 Epoch을 300이상 설정하여 학습하도록 해봐야겠다는 생각이 들었다.
Dataset의 Image Size 조절
Roboflow를 이용하여 Dataset의 Transformation을 진행할 때, Image Size를 416x416으로 Stretch해서 사용하였다. YOLOv5s 학습에 사용가능한 최대 이미지 크기가 640x640 임을 고려하였을 때, 640x640으로 학습하였을 경우 성능이 더욱 좋았을 것 같다.
Reference
- Vehicle Detection in Urban Traffic Surveillance Images Based on Convolutional Neural Networks with Feature Concatenation / https://doi.org/10.3390/s19030594
- Are we ready for autonomous driving? The KITTI vision benchmark suite / https://ieeexplore.ieee.org/document/6248074
- Top 5 Autonomous Driving Dataset Open-Sourced At CVPR 2020 / https://analyticsindiamag.com/top-5-autonomous-driving-dataset-open-sourced-at-cvpr-2020/
- You Only Look Once: Unified, Real-Time Object Detection / https://arxiv.org/abs/1506.02640
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks / https://arxiv.org/abs/1506.01497
- You Only Look Once — 다.. 단지 한 번만 보았을 뿐이라구! / https://medium.com/curg/you-only-look-once-%EB%8B%A4-%EB%8B%A8%EC%A7%80-%ED%95%9C-%EB%B2%88%EB%A7%8C-%EB%B3%B4%EC%95%98%EC%9D%84-%EB%BF%90%EC%9D%B4%EB%9D%BC%EA%B5%AC-bddc8e6238e2
Role
- 이홍준 : 자료 탐색, 코드, 결과 분석, 블로그 작성, 영상 제작 및 녹음